GPT-GPT2 Roadmap
GPT to GPT2
# # Improving Language Understanding by Generative Pre-training
(GPT-1)
Unsupervised learning served as pre-training objective for supervised fine-tuned models, hence the name Generative Pre-training.
Objective : Unsupervised pre-training followed by supervised fine-tuning.
Limitations :
- Previous Supervised Learning requires large amount of annotated data.
- Failed for generalizing for particular task they are trained for.
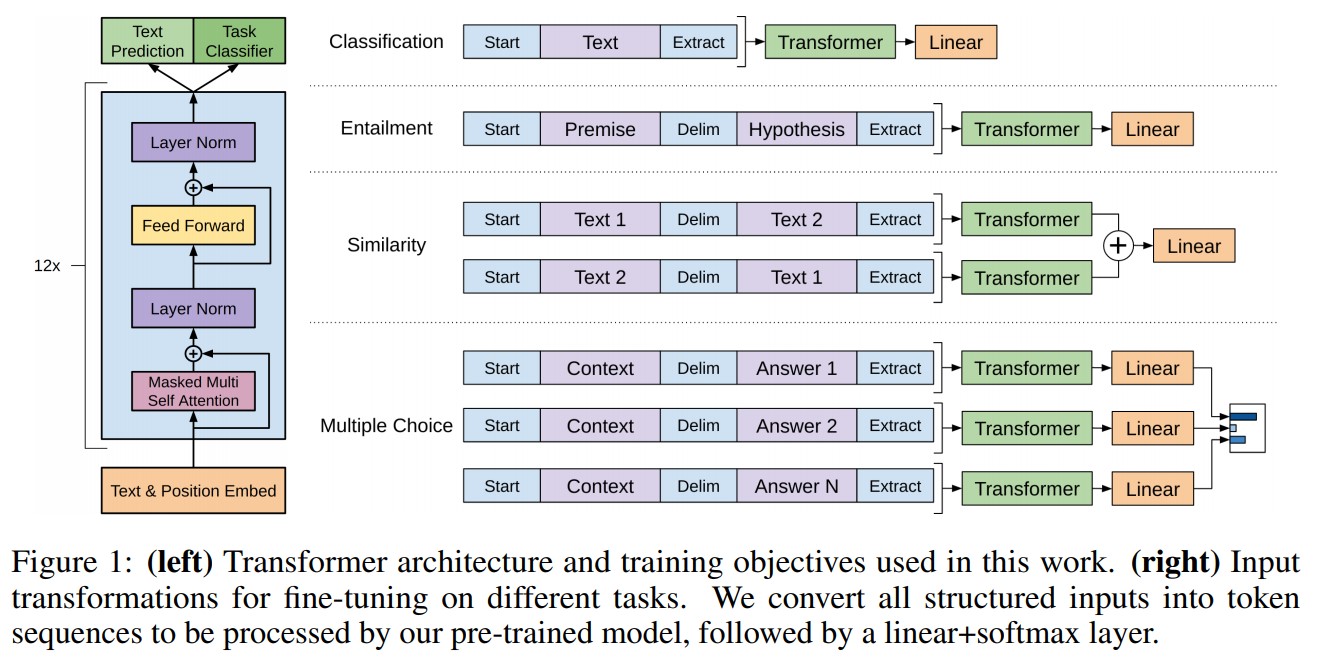
GPT Architecture :
Data Corpus
Concepts:
- Unsupervised Language Modelling (Pre-training): For unsupervised learning, standard language model objective was used.
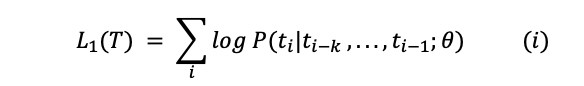
where T was the set of tokens in unsupervised data {t_1,…,t_n}, k was size of context window, θ were the parameters of neural network trained using stochastic gradient descent.
- Supervised Fine-Tuning : This part aimed at maximising the likelihood of observing label y, given features or tokens x_1,…,x_n.
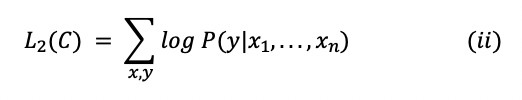
where C was the labeled dataset made up of training examples.
Instead of simply maximizing the objective mentioned in equation (ii), the authors added an auxiliary learning objective for supervised fine-tuning to get better generalization and faster convergence. The modified training objective was stated as:
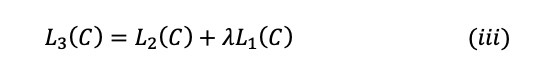
where L₁(C) was the auxiliary objective of learning language model and λ was the weight given to this secondary learning objective. λ was set to 0.5.
Supervised fine-tuning was achieved by adding a linear and a Softmax layer to the transformer model to get the task labels for downstream tasks.
- Task Specific Input Transformations : In order to make minimal changes to the architecture of the model during fine tuning, inputs to the specific downstream tasks were transformed into ordered sequences. The tokens were rearranged in following manner:
—Start and end tokens were added to the input sequences.
—A delimiter token was added between different parts of example so that input could be sent as ordered sequence. For tasks like question answering, multiple choice questions etc. multiple sequences were sent for each example. E.g. a training example comprised of sequences for context, question and answer for question answering task.
Implementation Details
Following are the implementation details:
-
For Unsupervised Training :
- Byte Pair Encoding (BPE) vocabulary with 40,000 merges was used.
- Model used 768-dimensional state for encoding tokens into word embeddings. Position embeddings were also learnt during training.
- 12 layered model was used with 12 attention heads in each self-attention layer.
- For position wise feed forward layer 3072-dimensional state was used.
- Adam optimiser was used with learning rate of 2.5e-4.
- Attention, residual and embedding dropouts were used for regularisation, with dropout rate of 0.1. Modified version of L2 regularisation was also used for non-bias weights.
- GELU was used as activation function.
-
The model was trained for 100 epochs on mini-batches of size 64 and sequence length of 512. The model had 117M parameters in total.
-
For Supervised Fine-tuning :
- Supervised fine-tuning took as few as 3 epochs for most of the downstream tasks. This showed that the model had already learnt a lot about the language during pre-training. Thus, minimal fine-tuning was enough.
- Most of the hyper parameters from unsupervised pre-training were used for fine-tuning.
Task Test
1.Question Answering

2.Semantic Similarity

3. Natural Language Inference

4. Text Classification

Model Performance:

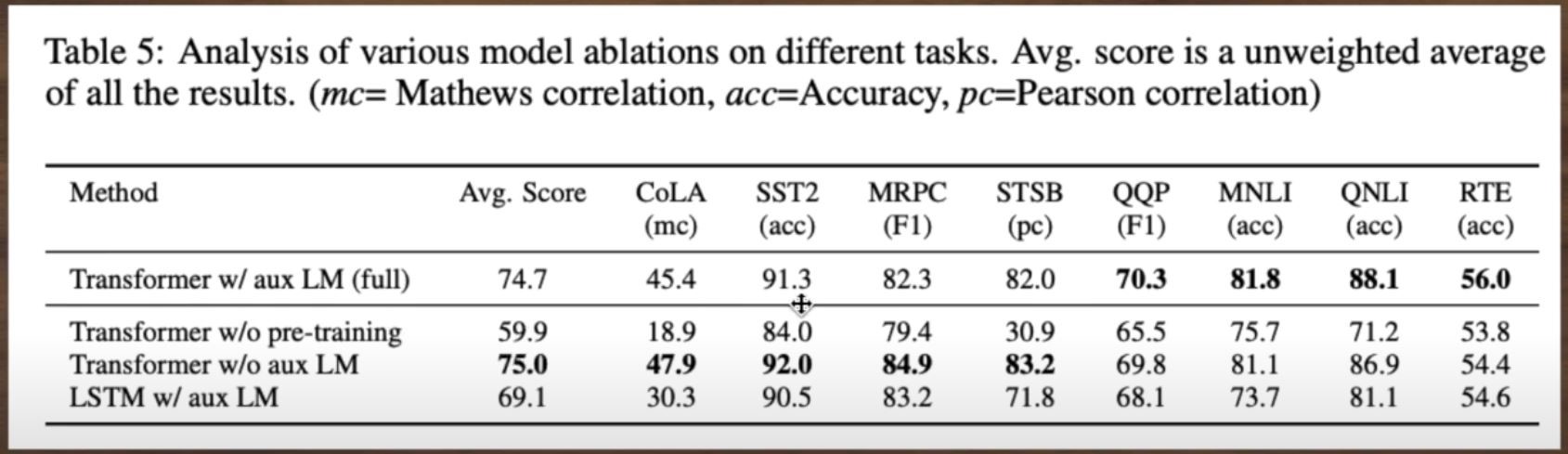
Ablations:
# # Language Models are unsupervised multitask learners (
GPT-2):
Its Stack of Decoder block of transformers with larger Dataset and more learning Parameters
Concepts:
-
Task Conditioning : We had seen that training objective of language model is formulated as P(output input). However, GPT-2 aimed at learning multiple tasks using the same unsupervised model. To achieve that, the learning objective should be modified to P(output input, task). This modification is known as task conditioning, where the model is expected to produce different output for same input for different tasks. _Some models implement task conditioning at an architectural level where the model is fed both, the input and the task. For language models, the output, input and task, all are sequences of natural language. Thus, _task conditioning for language models _is performed _by providing examples or natural language instructions to the model to perform a task. Task conditioning forms the basis for zero-shot task transfer which we will cover next. - Zero Shot Learning and Zero Short Task Transfer : An interesting capability of GPT 2 is zero shot task transfer. Zero shot learning is a special case of zero shot task transfer where no examples are provided at all and the model understands the task based on the given instruction. Instead of rearranging the sequences, as was done for GPT-1 for fine-tuning, input to GPT-2 was given in a format which expected the model to understand the nature of task and provide answers. This was done to emulate zero-shot task transfer behaviour. E.g., for English to French translation task, the model was given an English sentence followed by the word French and a prompt (:). The model was supposed to understand that it is a translation task and give French counterpart of English sentence.
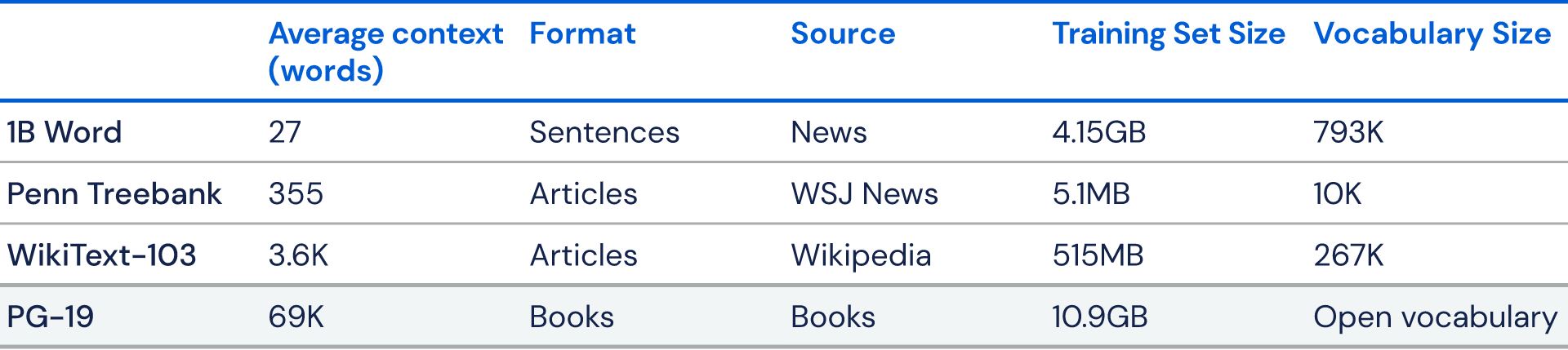
Data Corpus:
8 million Webpages
40GB of text data
Dataset name: "Webtext"
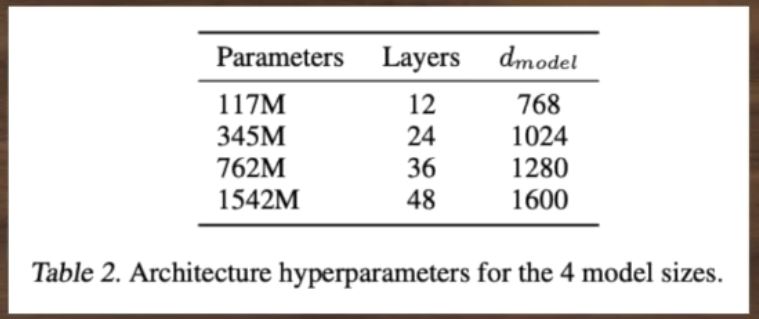
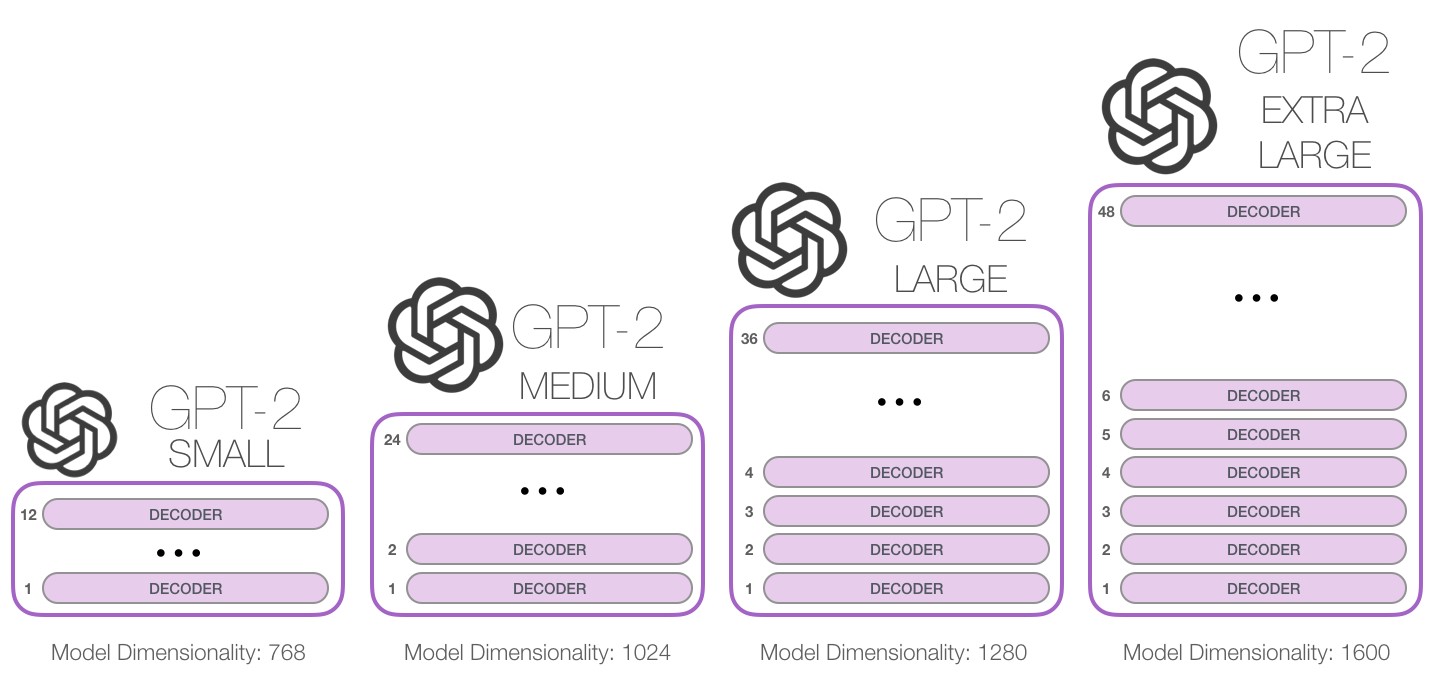
There are three released sizes of GPT-2:
- 124M (default): the "small" model, 500MB on disk.
- 355M: the "medium" model, 1.5GB on disk.
- 774M: the "large" model, cannot currently be finetuned with Colaboratory but can be used to generate text from the pretrained model (see later in Notebook)
- 1558M: the "extra large", true model. Will not work if a K80 GPU is attached to the notebook. (like 774M, it cannot be finetuned).
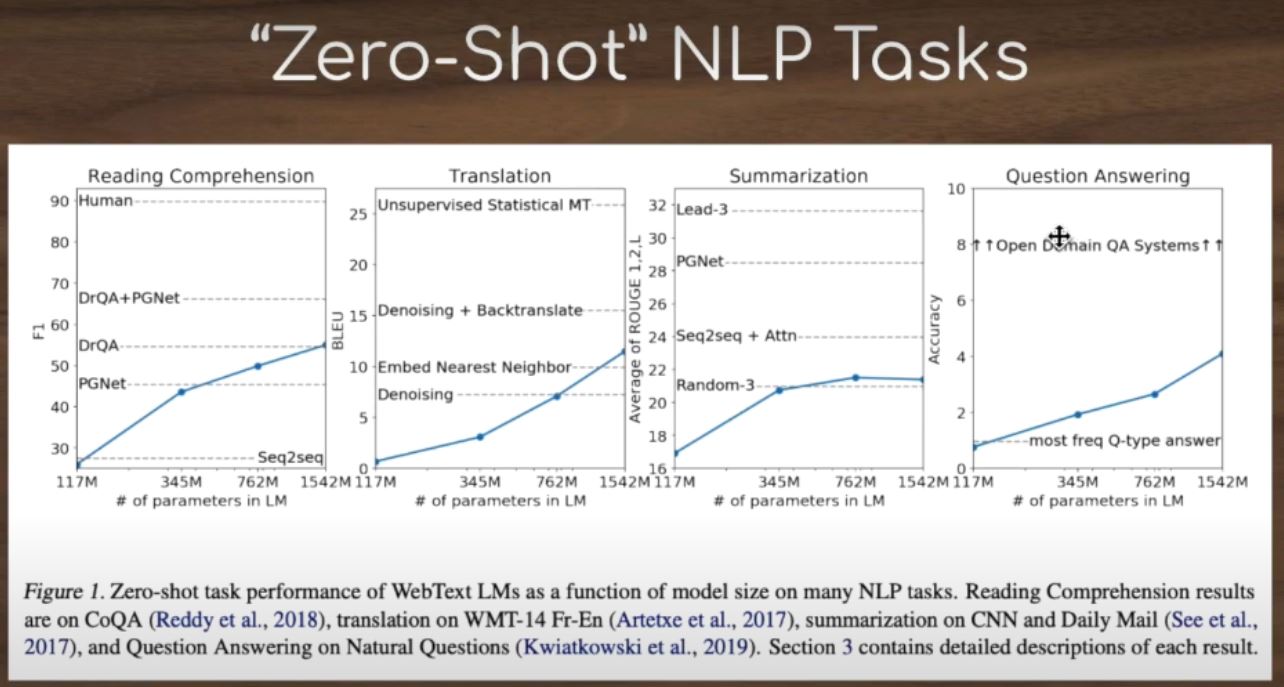
GPT2 Tasks
1.Question Answering

2.Translation:
![]()
3.Zero Shot NLP Task: Question answering, meaning answering without a context passage.
#
4.Turing-NLG: A 17-billion-parameter language model by Microsoft
#
#
| Question | Who was Jason Mraz engaged to? |
|---|---|
| Passage | Mraz was engaged to singer/songwriter and long-time close friend Tristan Prettyman on Christmas Eve 2010; they broke off the engagement six months later. |
| " Direct" Answer | Jason Mraz was engaged to Tristan Prettyman. |
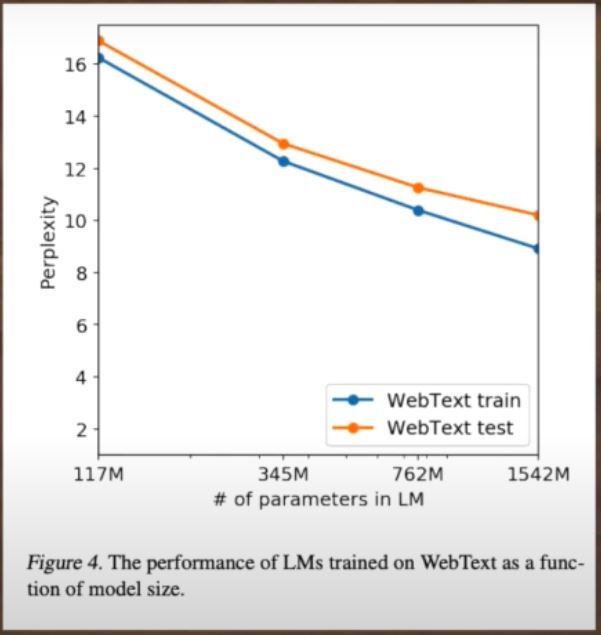
Model Performance:
Papers :
-
Discussion of GPT-1 paper (Improving Language Understanding by Generative Pre-training).
-
Discussion of GPT-2 paper (Language Models are unsupervised multitask learners) and its subsequent improvements over GPT-1.
-
Discussion of GPT-3 paper (Language models are few shot learners) and the improvements which have made it one of the most powerful models NLP has seen till date.
